If a Woodchuck Could Chuck Story Points
August 30, 2025
I spent a decade writing small fibonacci numbers in issue trackers (from 6-person startups to Google) in service of sprint planning. It hasn't ever helped forecast work, but I haven't been able to clearly articulate why until recently.
Log-normal
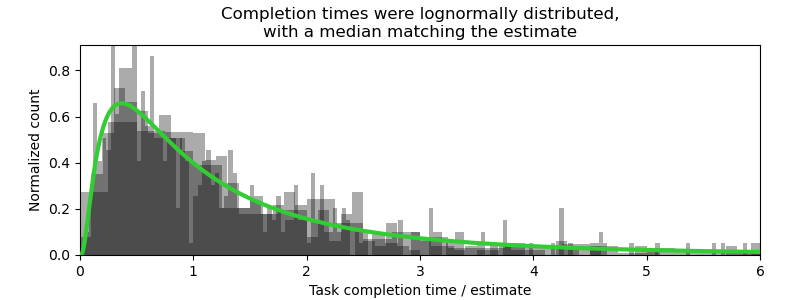
I found a pair of blog posts that both used data to show what the distribution of actual to estimated time taken for software development tasks was. Before we get to the distribution, I want to start from the bottom of the first post.
when you go to fix a bug or write a feature, [sometimes] you'll get it on your first try, but other times you have to come at it from two or three different angles before finding the answer. And then code review happens and you might need to make changes again. So completing a technical task can involve a "for" loop with a random number of iterations
This is true of larger projects too: imagine a project that has components A, B, and C. Maybe A can be solved with a 1-line configuration change in a vendor's product, maybe you can find a library that does it for you, or maybe you need to invent it whole cloth. If it turns out you need to write it all yourself, you'll need to write subcomponents D, E, and F. Maybe D can be solved by onboarding a vendor...
In both of these cases, the time it takes to do the work isn't the sum of a fixed number of uniformly distributed random variables. If they were, the actual to estimated time taken would follow a normal/Gaussian distribution (and I wouldn't be writing this blog post).
the lognormal emerges when random variables are not added but rather multiplied together
One way to think about the log-normal distribution is that if you estimate a task to be 8 points, it is as likely to be 4 as it is to be 16. It is also as likely to be 2 as it is to be 32. But you'll notice that if you have two tasks estimated at 8 points and they turn out to be a 4 and a 16, that's 20 points, not the 16 you estimated.
Both blog posts conclude that developers are quite good at estimating the median completion time but completion time has a log-normal distribution. Further, the mean is greater than the median in a log-normal, which unfortunately means there's a problem with...
Story Points
The pillar upon which all of scrum rests is that you can take a project, break it down into granular tasks, estimate those tasks, and then sum the estimates. Even if you are wrong about some estimates, the law of large numbers should bring overall completion time back to your estimate. But it turns out that's unsound because your estimates are medians of a log-normal. You're better off skipping all of that and just estimating the project as a whole.
This means that almost all the work you've done assigning points to tasks has had negative planning value.
This also means you can't just take a group of tasks and meaningfully predict a team's output by bin packing them into...
Sprints
Planning helps with 2 things that should not be conflated: coordination and forecasting. Sprint planning can help with coordination (you've decided what the team is working on in the next 2 weeks, but who is working on what?). Scrum rituals can help with coordination (a daily meeting where everyone is seated). But sprints cannot help with forecasting. Packing work into a sprint doesn't tell you when that work will be done.
Breaking work down to fit into a sprint does nothing. Consider: if you start a 5-point task on the last day of a sprint, should you break it down into smaller tasks? (Would you have broken it down if you had started it on the first day of a sprint?) Fitting tasks to sprints is a symptom of the tail wagging the dog: the arbitrary 2-week boundary dictates the planning process. Is the goal of breaking tasks down to have no work in-flight at the sprint boundary (at the next sprint planning meeting)?
A side-effect of breaking work down into sprint-packable tasks/tickets is it encourages the proliferation of tickets that end up being 1 or 2 points. These tickets have the same overhead as the only forecasting work that actually matters: the one thing that's going to blow up into 21 points. Planning should try to figure out which ticket is going to explode rather than spend any time on whether a 2 should be a 3.
Trying to "establish the team's velocity" by measuring the sum of completed story points comprised mostly of 1- and 2-point tasks over multiple 2-week periods is the least accurate thing to be doing. Smaller tasks have higher relative error but also don't matter. Forecasting a large project can't be done by estimating the completion time of its subtasks. And as the data from the two blog posts show, developers don't need help estimating (the medians of) completion times.
Accuracy vs Precision
Something I've been saying a lot recently is "the first 10% of planning produces 100% of the value". The last 90% of planning produces more precision without giving you more accuracy.
Initial planning gives you "this will take about 2 developer-months". Expending further planning effort refines that into "this will take 35 story points so we will finish on February 15th". Even though the second one is the output of summing a median of a log-normal and a Gantt chart, it's just so enticing with its precision. I think it's the ease with which you can produce precision that makes scrum so attractive.
In reality, only improving accuracy improves your forecasting. You'll know you've improved your accuracy when you've improved your confidence in your estimate. This can be by actually narrowing the confidence interval or by discovering information that de-risks your initial estimate. But that's hard to do and rarely done. If you haven't gained confidence in your forecast, all you have is more precision, not accuracy.
Write-only Issue Trackers
Finally, a word about backlogs. The supposed benefit of grooming a backlog is to keep the best tasks (highest urgency or best impact/effort ratio, often collectively modelled as highest "priority", sometimes with dependency sequencing thrown in) at the top is that people know what to work on next.
My experience is that issue trackers are mostly write-only, but especially backlogs. This is another way of saying: the team makes a plan somewhere else (ad-hoc planning document or in a live meeting) and then records it in the issue tracker. I wish this alarmed people more: the only time an issue tracker has value is when you read from it. If you only interact with the tracker to write to it, all it's doing is wasting your time.
For backlogs in particular, I think the biggest problem is that software developers are pretty fungible but not fungible at the granularity of small tasks. Some people will be more familiar with a task than others. If it's not urgent and we don't care to spread the context around, we can wait until they are free to work on it. (If we do intentionally want to spread the context around, we will wait until the uninitiated are free to work on it.) The actual amount of shared work you could assign to anyone ends up being quite small.
This actually reveals the best use-case for a shared backlog: low-context tasks. Starter tasks for when you need to onboard a new teammate, highly exploratory prototyping work, quick bugs.